
1. Top 3 Things Founders Get Wrong in EPD in the early Growth stage
The most common engineering challenges in the early growth stage are:
- Underinvesting in engineering recruiting.
- At the early stages of growth, you likely do not have a refined narrative or engineering brand
- Out of every five coffee chats, Tido estimated only one turns into a potential hire for interview
- Therefore, you need to overinvest in building out your engineering recruiting muscle early on
- It will get easier over time as the pitch is refined and the engineering brand gets out into the market, but most companies at this stage are not spending nearly enough time on talking to candidates
- Maintaining shipping velocity and craft as the team scales.
- Three years ago, the core problem was that adding more engineers slowed the team down.
- Today the problem has inverted: AI tools have made prototyping so fast that teams are shipping without enough rigor, and the balance between speed and taste is getting lost. This is a universal challenge - even Cursor, a company building many of these tools, is dealing with it internally.
- Having the right engineering leader who drives engineering recruiting
- The core job of an engineering leader has not fundamentally changed: recruit a world-class team, develop that team, and create clarity on the top priorities.
- What has changed is that creativity matters more than before, particularly around recruiting, and there is a higher premium on leaders who are willing to throw out old playbooks and adapt to how engineering work is changing.
This session focused primarily on shipping velocity and engineering leadership - #2 and #3 above.
2. Structuring Teams for Quality AND New Products
Labs vs Established Teams
- The bottleneck in engineering has shifted. Writing code is cheap now. The real constraints are testing, verification, deployment, code review, and making sure a growing codebase does not become a liability.
- When Cursor was at ~150 engineers and growing 10-20% headcount per month, the team had been built around an exceptionally strong prototyping skill set. The speed from idea to production-ready software was faster than anything in recent memory
- For example, when a new model turned out to be good at computer use, the team spiked to build Browser Mode and shipped it remarkably fast.
- But treating everything like a prototyping exercise stopped working for the one-to-100 type missions
- Specific problems that emerged: a billing ledger that was slightly incorrect (off by 1-2%, which is unacceptable for large enterprise customers who need to tie invoices to individual users), poor internal developer experience, and core SLOs on response times that were not nearly high enough.
- The company also had millions of paid weekly active users, which meant the need to dot i's and cross t's on features was growing faster than the prototyping-oriented team could handle.
- The approach that emerged was to intentionally separate two modes of building: One or two "labs" teams - small groups of former founders working on zero-to-one incubation projects.
- These teams have a slightly different working style and vibe, and they focus on things that are roughly nine months out and that no customer has quite asked for yet.
- These teams look different - they are made up of senior and staff engineers who play a more founder-like role, aren’t bound to adhere by specific processes, and can experiment more
- These teams have a slightly different working style and vibe, and they focus on things that are roughly nine months out and that no customer has quite asked for yet.
- The rest of the engineering org is structured more like a standard (but extremely high-talent-bar) software engineering team, focused on scaling, reliability, enterprise features, and infrastructure. This includes a dedicated platform and infrastructure team, an enterprise team working closely with GTM on revenue systems and governance features, and core product teams.
- As labs projects get close to initial GA, they are handed off to the standard teams for long-term ownership.
- At Klaviyo, a similar instinct led to running an internal experiment: standing up a new product team with a completely different set of rules and structure, separate from the existing org.
- The idea is to treat it like an A/B test - put people in a different type of environment and see if they move faster.
- This kind of internal experimentation is useful for surfacing blind spots in how teams are operating.
- The idea is to treat it like an A/B test - put people in a different type of environment and see if they move faster.
The Atomic Unit for Engineering Teams
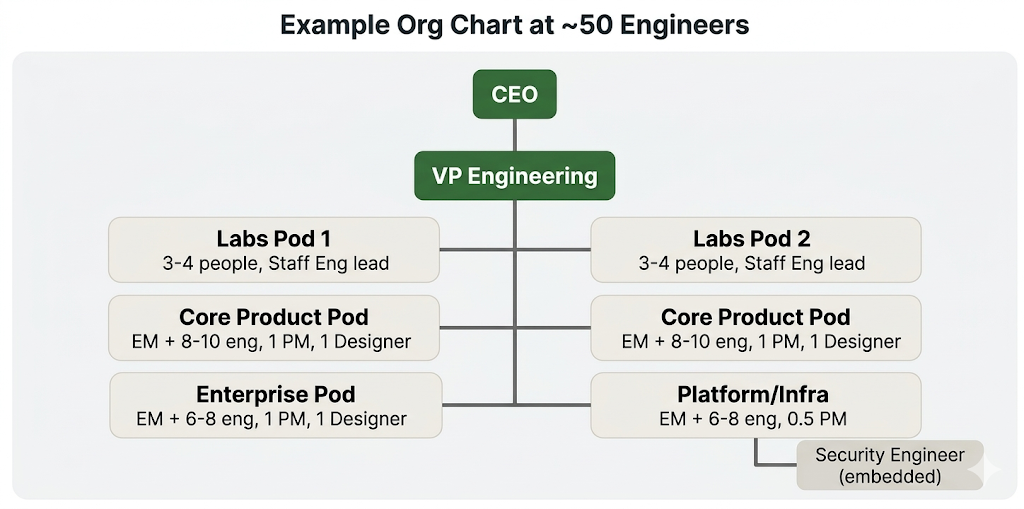
- A common question at this stage is how to structure the most atomic unit of the engineering team. A typical structure is pods of 8-10 people, with an engineering manager who is more people-oriented and a tech lead who is more execution-oriented.
- This is a reasonable setup, and it often emerges naturally as early managers start to scale out of being hands-on with every task.
- The key principle is that people management reporting lines do not have to mirror how work is actually structured. Teams should not be constantly reorged just because project assignments change. The manager stays stable; the project structure can flex.
- This is a reasonable setup, and it often emerges naturally as early managers start to scale out of being hands-on with every task.
- Engineering managers should be genuinely technical. The model where the EM is purely a people manager and all technical decision-making is delegated to a separate tech lead is not ideal.
- The tech lead role works well for specific large projects with significant dependencies and complexity, but the EM should still have enough technical depth to create clarity on direction.
- What matters most is that people managers are truly owning outcomes:
- Driving excellent hiring results end-to-end (not just sitting in on interviews while the founder does the actual recruiting)
- Holding the team to a high performance bar (including making hard decisions on underperformers)
- Creating clarity for the team about what the most important things to work on are
- As a manager's span grows beyond 8-12 people, the natural evolution is for tech leads to emerge underneath them. This is a sign that the manager is growing from an entry-level manager into a senior manager or director.
- That progression is healthy as long as the manager continues to drive hiring, firing, and clarity creation outcomes - not just running process and one-on-ones.
Engineering & Staffing Ratios Haven’t Changed that Much
- In terms of scope per engineer, each person now typically owns roughly 5x what would have been considered a reasonable scope for a 3-4 person team in a prior era.
- The hiring bar is more senior - mostly high-end staff engineers - and the expectation is that each person covers dramatically more ground than would have been normal a few years ago.
- Eng-to-PM ratios have not changed dramatically from past norms. Most product engineering teams have roughly one PM for every 5-10 engineers, skewing slightly more PM-heavy in enterprise areas with high ACV customers, and lighter (1:15 or even 1:30) in infrastructure.
- The first two PMs at Cursor were only recently hired at ~100 engineers, specifically because the team was no longer its own ICP for enterprise governance features and new user experience optimization.
- Design ratios may actually need to be heavier than in the past. Where the old rule of thumb was one designer supporting two PMs, it may now be closer to 1:1, because there is more work on both the early-stage product exploration side and the end-of-conveyor-belt polish side.
PM vs EM
- Spend significant time together before the hire is finalized. Both the CEO and the engineering leader need to know that they can have productive, reasonable discussions on hard problems before day one.
- Discovering how the working relationship functions after the person has already started is a risk.
- The best engineering leaders think beyond engineering as a function
- The more excited they are about the end customer problem, the business model, and the product - not just the technical execution - the more impact they will have. Business judgment in an engineering leader is rare and very valuable.
- The EM-PM partnership is critical and needs to be deliberately structured
- The failure mode is when the engineering leader is focused on tech debt and the product leader is focused on shipping faster, and the two create tension rather than shared accountability.
- Mechanisms that force alignment include:
- Preparing feather reviews jointly
- Co-leading weekly demos
- Ensuring that both the EM and PM think of the vertical product pod as their first team rather than their functional reporting chain.
- Product-led vs. engineering-led is not the right framing. Product and engineering need to operate as a single unit.
- The more useful question is whether the R&D organization as a whole is driving what the company should be working on, vs. having the roadmap driven primarily by the sales cycle or GTM function.
When and How to Build a Security Team
- There are three distinct security disciplines, and they require different profiles and hiring approaches. The suggestion is to build your security team at ~50 people
- Security engineering (application security + cloud/infrastructure security):
- This is the first hire. The goal is to find a very talented security engineer who can operate effectively in an early-stage environment.
- This is a genuinely difficult hire for two reasons:
- The average security professional is drawn to rules and systems by the nature of their work. Finding one who enjoys the ambiguity and pace of an early-stage startup is uncommon.
- Security professionals tend to be risk-averse. Compensation expectations typically skew toward higher salary and lower equity tolerance, because the risk-reward profile of a startup runs counter to what most security professionals are looking for.
- A useful framing for the role: position it as a career growth path to CISO. If the candidate understands that they will build out GRC, IT, and other security functions underneath them over time, a strong security engineer will take on compliance work as part of their growth trajectory even if it is not their core interest.
- This is a genuinely difficult hire for two reasons:
- This is the first hire. The goal is to find a very talented security engineer who can operate effectively in an early-stage environment.
- GRC (governance, risk, and compliance):
- One GRC person can scale the function for a meaningful period. If the business is enterprise-heavy and the GRC load is driven by sales (filling out security questionnaires, managing compliance certifications), a technical sales resource can flex halfway into GRC land as an interim step before a full-time GRC hire is justified.
- IT:
- The standard ratio is roughly 70 employees to one IT person. At 50 people, the company is about ready for a first dedicated IT hire, particularly if that person also handles employee onboarding and physical office security.
- At the CISO level, the leader can come from either security engineering or GRC ranks, depending on the business need.
- At Segment, the CISO came from the GRC side, which turned out to be critical for enabling enterprise sales.
- At Cursor, the security leader came from infrastructure engineering. Both models worked well.
- A strong model for organizational structure is to embed infrastructure security inside the infrastructure engineering team rather than keeping it as a separate function.
- This avoids the "throw it over the wall" dynamic where security identifies problems but needs to pull resources from other engineering teams to actually fix them.
- When security engineers sit inside infra, the work of reducing risk can happen directly.
- At Segment, the security team eventually had four functions: application security, cloud security (more SRE-type roles running the SIEM), GRC, and IT
- At Cursor, application and cloud security are combined because the profiles ended up being similar enough
Example Org Chart at ~50 Engineers
3. Speed and Quality
Generating Code is Not the Problem - Engineers are at 3-4x the Productivity
- The volume of code being generated has increased significantly, and the bottleneck has moved from writing code to reviewing, testing, and deploying it.
- The most straightforward investment is to throw compute at verification tasks.
- Vulnerability scanning can run in the background against every PR that gets submitted, as well as architecturally across the system.
- Cursor has built a number of these automated scanning tools and has invested heavily in tuning what comes back so the signal-to-noise ratio is high.
- The most straightforward investment is to throw compute at verification tasks.
- The class of slightly “boring” things to go check - style guide compliance, known vulnerability patterns, common error cases - is exactly what AI is good at.
- Most teams have not invested enough in automating these checks. The “no-brainer” compute spend is taking the most boring manual review tasks and paying for the tokens to automate them.
- The emerging frontier is around making large AI-generated PRs reviewable by humans
- When a 15,000-line PR comes in, the reviewer needs the PR broken down into walkable chunks with risk scoring per chunk, so they know where to spend their time. Think of it as a "code tour" for AI-generated code.
- Cursor is working on changing the code review surface to support this and expects to have something in market within a couple of months.
- On pricing for automated code review: Claude recently started charging $15-25 per code review, which was notable as the first time real dollars were put against what had been a seemingly free capability. How the economics of automated code review will play out is still unclear.
Framework: Klayvio’s Framework for AI-Assisted Development
- At Klaviyo, a framework was developed to give the entire engineering team a shared language for how AI-assisted development works:
- Level 1: Writing boilerplate and tests with AI assistance (where most teams were roughly 18 months ago)
- Level 2: Delegating meaningful chunks of work to AI, but still one change at a time with full human control
- Level 3: Agent-driven development where most code is AI-generated
- Level 4: Metric-driven delegation, where you give the system a metric and ask it to move that metric (not yet achieved industry-wide)
- Setting an explicit organizational goal (e.g., "the entire engineering team will be working as Level 3 engineers by end of Q2") is useful because it surfaces the real bottlenecks - code review, testing, deployment, guardrail enforcement - and creates urgency to solve them.
- At Klaviyo, a dedicated "AI Development Foundations" team was formed (separate from the existing dev infra team) to work specifically on encoding standards, guardrails, and solving these bottlenecks.
Example: How Klayvio Built Their Internal Engineering Observability System
- At Klaviyo, an internal system was built in roughly three weeks that connects all engineering tools - Linear (for task tracking), Incident IO (for incidents), Confluence (for documents), and the system where company OKRs are stored and scored - and allows natural language queries across all of them.
- This replaces the previous process of manually asking someone to generate status updates, which is both slow and, for the person doing it, not a rewarding use of their time.
- The system can answer questions like: "What did this team work on last week?", "How are they tracking against their goals?", "What are the execution risks across the board?", "What were the patterns of incidents over the past week?"
- It generates PDF-style reports per team that include:
- A summary of current status
- Headcount and open roles
- What was shipped and completed
- Blockers and risks
- Automated risk assessments
- The approach is to connect internal tools via MCP, then use natural language queries to pull information across them
- The system was built with about three weeks of engineering time and works well.
- Currently the interface is command-line based (built by engineers, for engineers), but the plan is to make it more user-friendly over time.
Prototyping is Ok, But Build in Progressive Gates to Kill Projects Early
- The common failure mode is letting teams go deep on an idea for many weeks, at which point the sunk cost makes it very difficult to kill the project even if it is not the right direction.
- The approach that works better is progressive gates of rigor and de-risking:
- First, build a cheap prototype (an HTML prototype can be built in a couple of days with current tools). Show it to leadership before investing further.
- Then identify the scariest de-risk test. For example: show it to the five biggest customers and see if any of them are genuinely excited. If none are, put it on ice.
- The principle is to have the hard conversation about whether to continue when the team is least committed to the idea. Killing something after two days of investment is much easier than killing it after eight weeks.
- Product reviews should be happening much earlier in the process than they typically do
- The temptation with current AI tools is to just vibe code something and get it almost production-ready before ever getting rigorous feedback. But if eight weeks of engineering time have gone in and the product idea turns out to be wrong, it becomes nearly impossible for leadership to say no.
- At Cursor, the challenge is that an unusually bottoms-up culture means multiple teams sometimes land on similar ideas in parallel without enough coordination. The company is working toward getting leadership alignment earlier through product reviews, before significant resources are committed.
Example: Klayvio’s “Table Flip” Approach to Reduce the Pre-Coding Process
- At Klaviyo, their approach to building rigor around experiments was to dramatically reduce pre-coding process. Internally branded as "Table Flip," the idea was to speak with prototypes rather than with long PRDs and RFC design documents.
- The goal was to shrink the time spent talking about work relative to the time spent doing the work.
- Teams that were spending weeks writing documents before writing a line of code were pushed to prototype first and validate with real usage.
Velocity and Quality Metrics
- Standard DORA metrics remain the right starting point for measuring engineering health
- Nearly everyone is looking at the same core set, especially during this period of rapid change in how code is written
- Velocity metrics:
- PR throughput
- Cycle time
- Feature shipping velocity
- Autonomous PR rate (a newer metric that reflects the proportion of AI-generated code).
- Quality metrics:
- Bugs out of SLA
- Incidents
- Mean time to detection
- Mean time to respond
- Mean time to resolve
- Change failure rate.
- Operational metrics:
- Security posture
- Infrastructure costs
- A useful onboarding metric: time to first PR and time to 10th PR for new engineers
- As the team scales, these numbers tend to slip, and that is a leading indicator that dev infrastructure and onboarding are not keeping up with growth.
- At Klaviyo, a snapshot of these metrics is maintained and reviewed regularly. For smaller companies, not all of these will be relevant, but having some form of broad observability across velocity and quality is important.
- In terms of actual productivity gains from AI tooling: the very best engineers who are fully leaned into the tools are seeing roughly 3-4x leverage. But that is a small fraction of the overall market.
- The blended throughput gain across most engineering teams is closer to 50%, though it is accelerating quickly, particularly since the latest round of model improvements.
- These metrics should not be treated as gospel. Not all code is created equal, and the business-level lens still matters - whether customers are more delighted, whether revenue is growing, whether the team is hitting the initiatives that actually move the business
- But bottoms-up metrics are useful for understanding what is happening and identifying teams that may be struggling.
Create Rituals That Encourage Speed: Tido’s Friday Demo
- A weekly Friday demo meeting is one of Tido’s most effective execution rituals for maintaining shipping velocity.
- This ritual was used at Segment and is now being rolled out at Cursor in a very similar form. At Klaviyo, a similar Friday product review format was adopted and had the same effect of keeping teams at pace.
- The expectation is that every single person in the meeting demos what they built that week and briefly talks about what they will work on the following week.
- The meeting serves two purposes simultaneously: it creates momentum (people looWhat to Look Forward to showing off their work) and provides light accountability (if someone has two weeks in a row where they don't have much to demo, that is a useful signal that something may not be going well - though the conversation usually happens outside of the meeting itself).
- The ideal size is 8-10 people. If engineering managers and PMs also demo and set a high bar for what a good demo looks like, the quality of the meeting improves quickly over time.
- It takes a few weeks to get this meeting to a good place. There will be initial resistance, particularly from infrastructure teams whose work operates on longer cycles. The key is to push through that resistance, because the discipline of chunking up work into visible weekly increments is valuable even when the underlying project spans multiple weeks. It is not about constraining the time horizon of projects - it is about ensuring there is visible forward progress every week.
Create Rituals that Encourage Output Quality: The Feather Review
- A feather review is a structured retrospective that can be called at any time by any leader or team member. It functions as a lightweight mini board report for a team.
- The name "feather" is intentional - it should take no more than one hour to prepare. The goal is for the author to write down their current thinking, not to spend a week building a presentation.
- The format is a written document, circulated as a pre-read 24 hours in advance. It covers:
- Team resourcing and headcount
- Most recent goal grading
- A postmortem of what went well and what went poorly
- Once the pre-read is circulated, leadership reads it carefully and adds discussion questions in advance of the meeting, including pointed critique questions. This preparation leads to a focused, high-quality discussion.
- Feather reviews can be used recursively across the org. They are often a more natural way to reason about how a team is performing than traditional horizontal calibration or formal performance review processes, because they bring the EM and PM together to jointly assess the state of the team.
- The EM and PM should always prepare the feather review together.
- Having the EM and PM operate in separate accountability chains - where the EM is focused on tech debt and the PM is focused on shipping faster - creates tension. The feather review is one mechanism for forcing shared accountability.
- A useful quality signal: if the leader preparing the feather review is not aware of what is going wrong on their team, that is a sign they may not be scaling effectively in their role
Build a Structured Bug-Reporting Process
- As the product scales and the customer base grows, having a structured bug reporting process becomes increasingly important. The goal is to have one unified channel through which the entire field (sales, customer success, support) can report bugs and issues.
- The technical support engineering (TSE) team serves as the first line of defense, deflecting and answering as many tickets as possible.
- When the TSE team cannot resolve an issue, there is an escalation process into the engineering teams.
- The key metrics to track are:
- Rate of escalated bugs per customer
- The team's ability to meet SLOs on response time by priority level (e.g., if a bug is reported as high priority, there should be a defined time SLO for how long it takes to get back to the reporter).
- The key metrics to track are:
- If engineering teams are consistently missing their escalation SLOs, the field cannot trust the process, which creates a breakdown in the feedback loop between customers and engineering.
- Some areas of the product may be hopelessly behind on bug queues while others are doing quite well. Having visibility into this unevenness is important for allocating engineering resources.
Staying Close to Customers
- One of the bottlenecks that has not changed much despite AI tooling improvements is the work of talking to customers and building a good synthesis of what is happening in the market.
- If engineers working on a feature have not talked to 5-10 customers, they should go do that before building.
- At Klaviyo, the approach is to build products together with existing customers from the start.
- For newer, more autonomous product directions, they actively recruit a cohort of customers who want to give very early feedback on rough products
- The engagement from existing customers who want to co-build is typically high
Example: How Cursor Stays Close to Customers
- There is one dedicated user researcher at Cursor, but the belief is that every single person at the company can and should talk to customers.
- It is a skill set that everyone should be building, and it will make them stronger at their core role.
- Cursor maintains a customer advisory board run by the technical account management team, used primarily for validating enterprise feature directions and ROI stories. But that structured channel serves only a small fraction of the questions the team has.
- Most customer feedback is gathered more ad hoc - engineers are encouraged to talk directly to former coworkers at companies like Stripe and Notion to get the unfiltered reality of how the product is being used.
- Being a dev tools company where the builders are also the users is a competitive advantage, but it also creates tunnel vision. The team can miss obvious problems that customers with different workflows are experiencing.
- There are things that large enterprise customers with 30,000 seats care about - admin governance, management, seat provisioning - that no one on the internal team is naturally thinking about. That is where PMs and customer feedback loops become essential.
4. Head of Engineering
What to Look For and How to Evaluate a Head of Eng
- The median time to hire a head of engineering before AI was 9-11 months. The timeline may have gotten longer.
- The core job has not fundamentally changed. It is:
- Recruit a world-class team
- Develop that team into something where the whole is greater than the sum of the parts
- Create clarity on the top priorities to drive business impact.
- This was the job at Segment 10 years ago, and it is the same job at Cursor today.
- What has changed is that creativity matters more, especially in recruiting
- Building a strong engineering team without a major brand behind you requires genuine creative thinking - the standard recruiting playbook does not work as well at smaller companies
- Look for someone who has successfully built teams without the benefit of a Facebook or Dropbox brand behind their back.
- Look for someone who is explicitly willing to throw out old playbooks. The way engineering work is done is changing rapidly, and a leader who is energized by figuring out new ways of working will outperform someone running a familiar playbook.
- Building a strong engineering team without a major brand behind you requires genuine creative thinking - the standard recruiting playbook does not work as well at smaller companies
- The anti-pattern is hiring someone who will apply an old playbook without adapting to the current environment.
- The best engineering leaders are first-principles thinkers with strong business judgment - the kind of person who could be a founder themselves.
- To evaluate a candidate, simulate real work together before making the hire
- Spend meaningful time (15-20+ hours over 1-2 weeks) working through actual business problems together in shared Google Docs
- Share real problems the company is facing and see how the candidate thinks through them.
- At Segment, this is how the founders got conviction on the VP Engineering hire - they spent a couple of weeks simulating work on the company's biggest problems.
- The edge in hiring is the ability to identify talent that is not immediately obvious from the resume. If the resume makes it clear that someone is elite, every top company is already trying to recruit that person.
- Some of the best hires come from candidates whose profiles do not look exciting on paper but who are clearly exceptional when you work with them directly.
- When sourcing candidates, referral-based sourcing through VCs and the VC network tends to produce stronger candidates than third-party recruiters. VCs generally have a better sense of who is genuinely excellent.
The CEO-Engineering Leader Relationship
- Spend significant time together before the hire is finalized. Both the CEO and the engineering leader need to know that they can have productive, reasonable discussions on hard problems before day one.
- Discovering how the working relationship functions after the person has already started is a risk.
- The best engineering leaders think beyond engineering as a function
- The more excited they are about the end customer problem, the business model, and the product - not just the technical execution - the more impact they will have. Business judgment in an engineering leader is rare and very valuable.
- The EM-PM partnership is critical and needs to be deliberately structured
- The failure mode is when the engineering leader is focused on tech debt and the product leader is focused on shipping faster, and the two create tension rather than shared accountability.
- Mechanisms that force alignment include:
- Preparing feather reviews jointly
- Co-leading weekly demos
- Ensuring that both the EM and PM think of the vertical product pod as their first team rather than their functional reporting chain.
- Product-led vs. engineering-led is not the right framing. Product and engineering need to operate as a single unit.
- The more useful question is whether the R&D organization as a whole is driving what the company should be working on, vs. having the roadmap driven primarily by the sales cycle or GTM function.
Comments